# Come See Elkeid at BlackHat- 阅读更多
Elkeid - Cloud Workload Protection Platform
聚焦威胁检测与安全运营
功能介绍
入侵检测
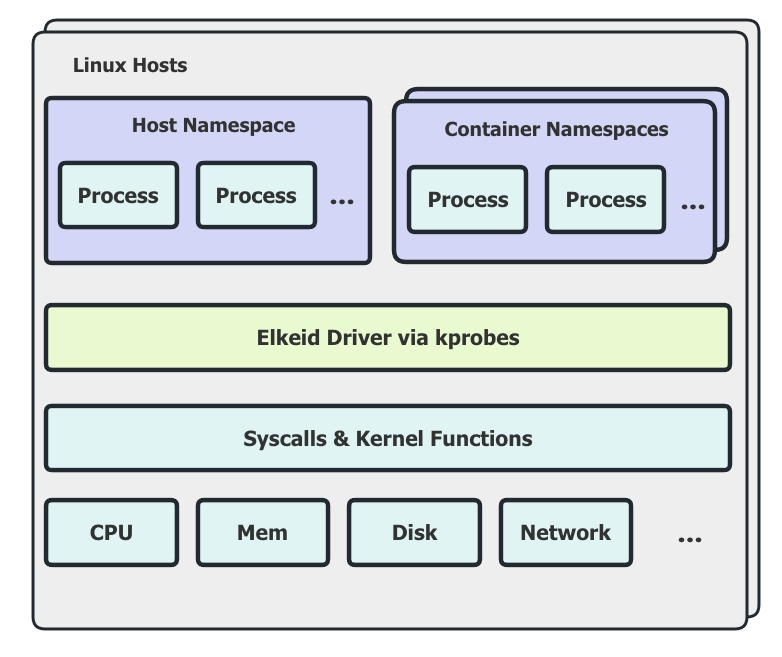
对主机与容器的入侵行为进行检测并提供处置方案,包括:反弹shell、本地提权、容器逃逸、后门木马、内核态后门、恶意命令、可疑命令序列、暴力破解等
RASP
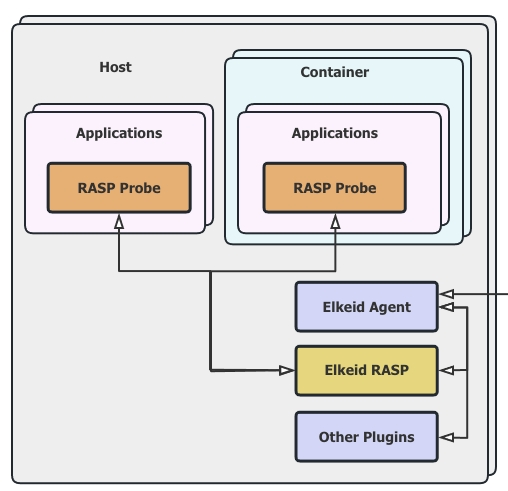
对应用运行时入侵行为进行实时检测并提供处置方案,包括:各类内存马、各类RCE、SSRF、ONGL注入、可疑命令序列等,且支持热补丁技术
云原生防护
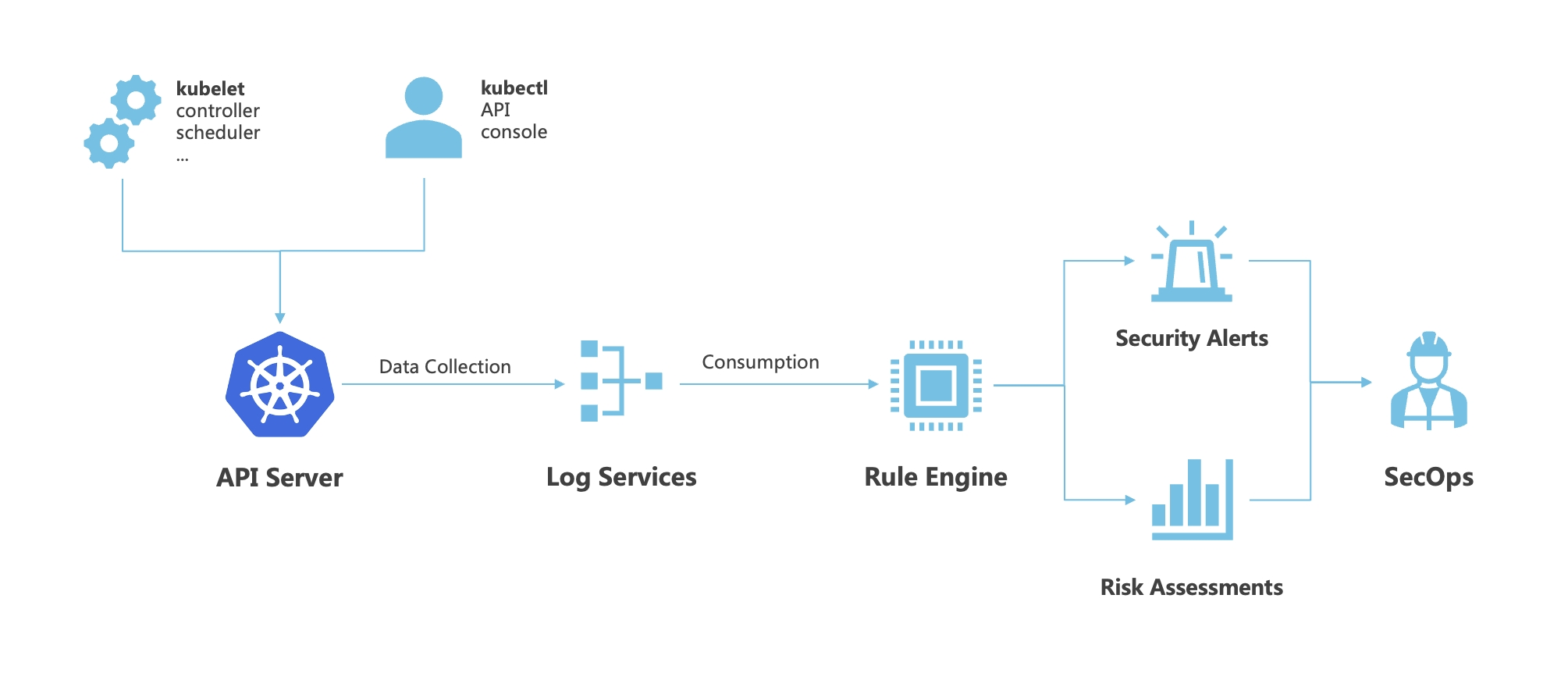
实现对云原生环境内的攻击行为、不安全资源实时监控,并提供对安全风险的溯源分析和大盘展示等能力。帮助企业进行入侵响应和风险分析。
资产盘点
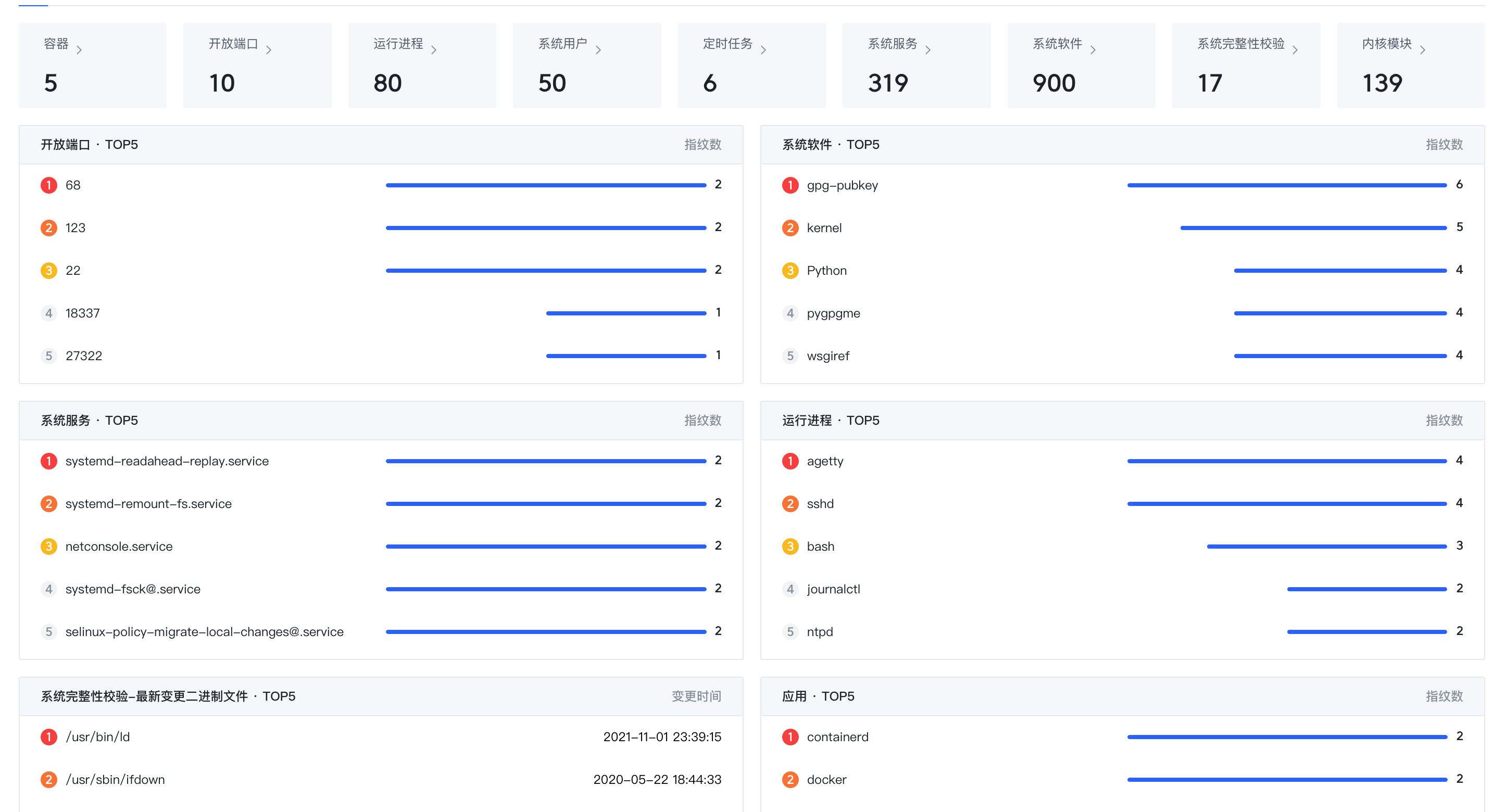
统一管理主机列表、容器列表、进程、Java进程依赖信息、端口、账号、系统组件、系统服务、定时任务、系统完整性等资产指纹信息,帮助企业资产可视化
漏洞检测
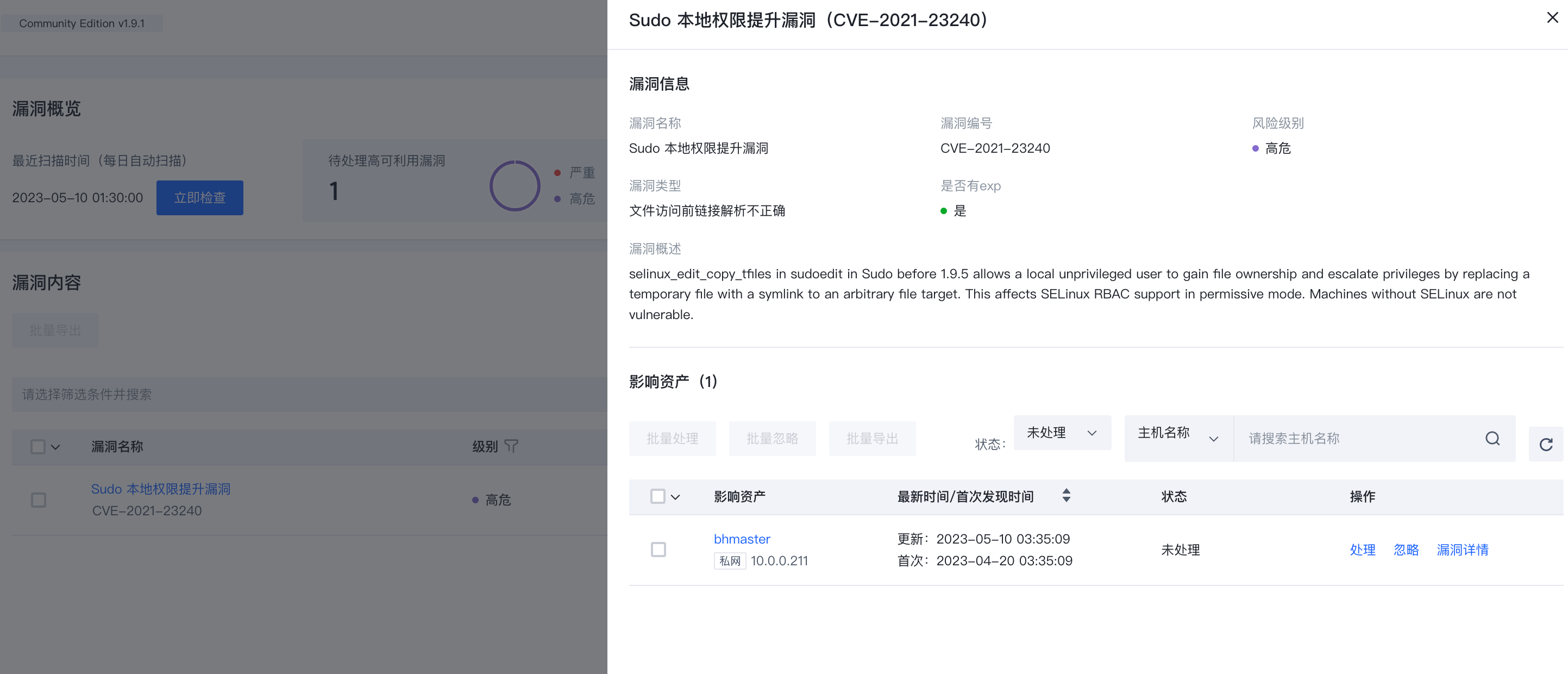
对主机、应用上存在的漏洞风险进行全面监测,包括系统组件漏洞、应用漏洞等,帮助企业应对漏洞风险
安全基线
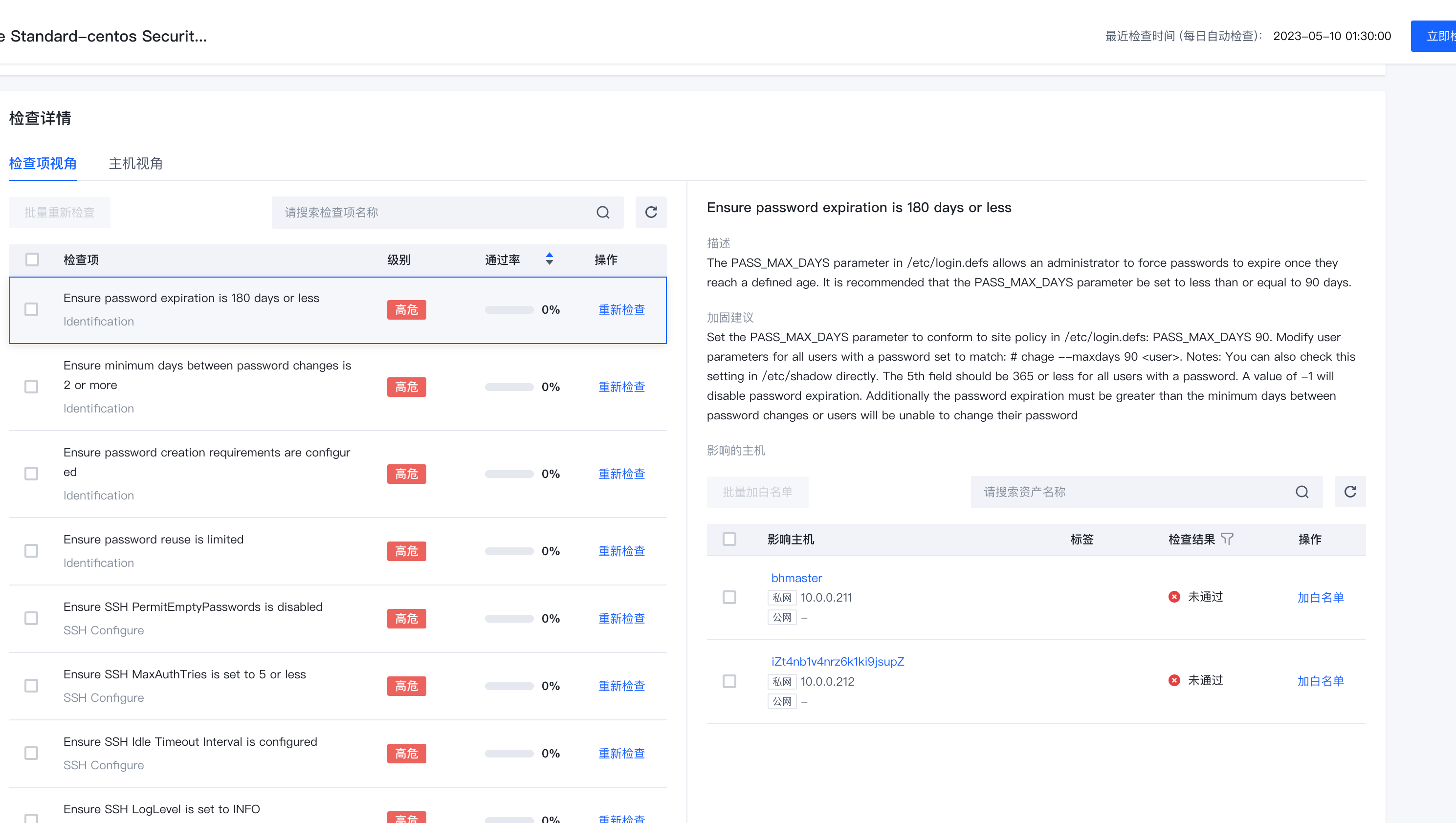
支持弱口令、等保二级、等保三级等基线标准检测,有助于您更好的管理服务器基线安全
使用案例
在线试用与商业版本咨询